
 Intel’s manuals for their x86/x64 processor clearly state that the fsin instruction (calculating the trigonometric sine) has a maximum error, in round-to-nearest mode, of one unit in the last place. This is not true. It’s not even close.
Intel’s manuals for their x86/x64 processor clearly state that the fsin instruction (calculating the trigonometric sine) has a maximum error, in round-to-nearest mode, of one unit in the last place. This is not true. It’s not even close.
The worst-case error for the fsin instruction for small inputs is actually about 1.37 quintillion units in the last place, leaving fewer than four bits correct. For huge inputs it can be much worse, but I’m going to ignore that.
I was shocked when I discovered this. Both the fsin instruction and Intel’s documentation are hugely inaccurate, and the inaccurate documentation has led to poor decisions being made.
The great news is that when I shared an early version of this blog post with Intel they reacted quickly and the documentation is going to get fixed!
I discovered this while playing around with my favorite mathematical identity. If you add a double-precision approximation for pi to the sin() of that same value then the sum of the two values (added by hand) gives you a quad-precision estimate (about 33 digits) for the value of pi. This works because the sine of a number very close to pi is almost equal to the error in the estimate of pi. This is just calculus 101, and a variant of Newton’s method, but I still find it charming.
The sin() function in VC++ is accurate enough for this technique to work well. However this technique relies on printing the value of the double-precision approximation of pi to 33 digits, and up to VC++ 2013 this doesn’t work – the extra digits are all printed as zeroes. So, you either need custom printing code or you need to wait for Dev 14 which has improved printing code.
So, I tried g++ on 32-bit Linux (Ubuntu 12.04) because I knew that glibc handles the printing just fine. However the results weren’t adding up correctly. I eventually realized that the sin() function in 32-bit versions of 2.15 glibc is just a thin wrappers around fsin and this instruction is painfully inaccurate when the input is near pi.
Catastrophic cancellation, enshrined in silicon
The first step in calculating trigonometric functions like sin() is range reduction. The input number, which Intel says can be up into the quintillion range, needs to be reduced down to between +/- pi/2.
Range reduction in general is a tricky problem, but range reduction around pi is actually very easy. You just have to subtract the input number from a sufficiently precise approximation of pi. The worst-case for range reduction near pi will be the value that is closest to pi. For double-precision this will be a 53-bit approximation to pi that is off by, at most, half a unit in the last place (0.5 ULP). If you want to have 53 bits of accuracy in the result then you need to subtract from an approximation to pi that is accurate to at least 106 bits – half the bits will cancel out but you’ll still be left with enough.
But you actually need more than that. The x87 FPU has 80-bit registers which have a 64-bit mantissa. If you are doing long-double math and you want your range reduction of numbers near pi to be accurate then you need to subtract from at least a 128-bit approximation to pi.
This is still easy. If you know your input number is near pi then just extract the mantissa and do high-precision integer math to subtract from a hard-coded 128-bit approximation to pi. Round carefully and then convert back to floating-point. In case you want to give this a try I converted pi to 192-bits of hexadecimal:
C90FDAA2 2168C234 C4C6628B 80DC1CD1 29024E08 8A67CC74
But Intel doesn’t use a 128-bit approximation to pi. Their approximation has just 66 bits. Here it is, taken from their manuals:
C90FDAA2 2168C234 C
Therein lies the problem. When doing range reduction from double-precision (53-bit mantissa) pi the results will have about 13 bits of precision (66 minus 53), for an error of up to 2^40 ULPs (53 minus 13). The measured error is lower at approximately 164 billion ULPs (~37 bits), but that’s still large. When doing range reduction from the 80-bit long-double format there will be almost complete cancellation and the worst-case error is 1.376 quintillion ULPs.
Oops.
Actually calculating sin
 After range reduction the next step is to calculate sin. For numbers that are sufficiently close to pi this is trivial – the range-reduced number is the answer. Therefore, for double(pi) the error in the range reduction is the error in fsin, and fsin is inaccurate near pi, contradicting Intel’s documentation. QED.
After range reduction the next step is to calculate sin. For numbers that are sufficiently close to pi this is trivial – the range-reduced number is the answer. Therefore, for double(pi) the error in the range reduction is the error in fsin, and fsin is inaccurate near pi, contradicting Intel’s documentation. QED.
Note that sin(double(pi)) should not return zero. The sine of pi is, mathematically, zero, but since float/double/long-double can’t represent pi it would actually be incorrect for sin() to return zero when passed an approximation to pi.
Frustration
It is surprising that fsin is so inaccurate. I could perhaps forgive it for being inaccurate for extremely large inputs (which it is) but it is hard to forgive it for being so inaccurate on pi which is, ultimately, a very ‘normal’ input to the sin() function. Ah, the age-old decisions that we’re then stuck with for decades.
I also find Intel’s documentation frustrating. In their most recent Volume 2: Instruction Set Reference they say that the range for fsin is -2^63 to +2^63. Then, in Volume 3: System Programming Guide, section 22.18.8 (Transcendental Instructions) they say “results will have a worst case error of less than 1 ulp when rounding to the nearest-even”. They reiterate this in section 8.3.10 (Transcendental Instruction Accuracy) of Volume 1: Basic Architecture.
Section 8.3.8 (Pi) of the most recent Volume 1: Basic Architecture documentation from Intel discusses the 66-bit approximation for pi that the x87 CPU uses, and says that it has been “chosen to guarantee no loss of significance in a source operand”, which is simply not true. This optimistic documentation has consequences. In 2001 an up-and-coming Linux kernel programmer believed this documentation and used it to argue against adding an fsin wrapper function to glibc.
Similar problems apply to fcos near pi/2. See this blog post for more details and pretty pictures.
Intel has known for years that these instructions are not as accurate as promised. They are now making updates to their documentation. Updating the instruction is not a realistic option.
I ran my tests on the 2.19 version of glibc (Ubuntu 14.04) and found that it no longer uses fsin. Clearly the glibc developers are aware of the problems with fsin and have stopped using it. That’s good because g++ sometimes calculates sin at compile-time, and the compile-time version is far more accurate than fsin, which makes for some bizarre inconsistencies when using glibc 2.15, which can make floating-point determinism challenging.
Is it a bug?
When Intel’s fdiv instruction was found to be flawed it was clearly a bug. The IEEE-754 spec says exactly how fdiv should be calculated (perfectly rounded) but imposes no restrictions on fsin. Intel’s implementation of fsin is clearly weak, but for compatibility reasons it probably can’t be changed so it can’t really be considered a bug at this point.
However the documentation is buggy. By claiming near-perfect accuracy across a huge domain and then only providing it in a tiny domain Intel has misled developers and caused them to make poor decisions. Scott Duplichan’s research shows that at long-double precision the fsin fails to meet its guarantees at numbers as small as 3.01626.
For double-precision the guarantees are not met for numbers as small as about 3.14157. Another way of looking at this is that there are tens of billions of doubles near pi where the double-precision result from fsin fails to meet Intel’s precision guarantees.
The absolute error in the range I was looking at was fairly constant at about 4e-21, which is quite small. For many purposes this will not matter. However the relative error can get quite large, and for the domains where that matters the misleading documentation can easily be a problem.
I’m not the first to discover this by any means, but many people are not aware of this quirk. While it is getting increasingly difficult to actually end up using the fsin instruction, it still shows up occasionally, especially when using older versions of glibc. And, I think this behavior is interesting, so I’m sharing.
That’s it. You can stop reading here if you want. The rest is just variations and details on the theme.
How I discovered this
I ran across this problem when I was planning to do a tweet version of my favorite pi/sin() identity
double pi_d = 3.14159265358979323846;
printf(“pi = %.33f\n + %.33f\n”, pi_d, sin(pi_d));
I compiled this with g++, confident that it would work. But before sending the tweet I checked the results – I manually added the two rows of numbers – and I was confused when I got the wrong answer – I was expecting 33 digits of pi and I only got 21.
I then printed the integer representation of sin(pi_d) in hex and it was 0x3ca1a60000000000. That many zeroes is very strange for a transcendental function.
At first I thought that the x87 rounding mode had been set to float for some reason, although in hindsight the result did not even have float accuracy. When I discovered that the code worked on my desktop Linux machine I assumed that the virtual machine I’d been using for testing must have a bug.
It took a bit of testing and experimentation and stepping into various sin() functions to realize that the ‘bug’ was in the actual fsin instruction. It’s hidden on 64-bit Linux (my desktop Linux machine is 64-bit) and with VC++ because they both have a hand-written sin() function that doesn’t use fsin.
I experimented a bit with comparing sin() to fsin with VC++ to characterize the problem and eventually, with help from Scott Duplichan’s expose on this topic, I recognized the problem as being a symptom of catastrophic cancellation in the range reduction. I’m sure I would have uncovered the truth faster if Intel’s documentation had not filled me with unjustified optimism.
Amusingly enough, if I’d followed my usual practice and declared pi_d as const then the code would have worked as expected and I would never have discovered the problem with fsin!
Code!
If you want to try this technique for calculating pi but you don’t like manually adding 34-digit numbers then you can try this very crude code to do it for you:
void PiAddition() {
double pi_d = 3.14159265358979323846;
double sin_d = sin(pi_d);
printf(“pi = %.33f\n + %.33f\n”, pi_d, sin_d);char pi_s[100]; char sin_s[100]; char result_s[100] = {};
snprintf(pi_s, sizeof(pi_s), “%.33f”, pi_d);
snprintf(sin_s, sizeof(sin_s), “%.33f”, sin_d);
int carry = 0;
for (int i = strlen(pi_s) – 1; i >= 0; –i) {
result_s[i] = pi_s[i];
if (pi_s[i] != ‘.’) {
char d = pi_s[i] + sin_s[i] + carry – ‘0’ * 2;
carry = d > 9;
result_s[i] = d % 10 + ‘0’;
}
}
printf(” = %s\n”, result_s);
}
The code makes lots of assumptions (numbers aligned, both numbers positive) but it does demonstrate the technique quite nicely. Here are some results:
With g++ on 32-bit Linux with glibc 2.15:
pi = 3.141592653589793115997963468544185
+ 0.000000000000000122460635382237726
= 3.141592653589793238458598850781911
With VC++ 2013 Update 3:
pi = 3.141592653589793100000000000000000
+ 0.000000000000000122464679914735320
= 3.141592653589793222464679914735320
With VC++ Dev 14 CTP 3 and g++ on 64-bit Linux or glibc 2.19:
pi = 3.141592653589793115997963468544185
+ 0.000000000000000122464679914735321
= 3.141592653589793238462643383279506
In other words, if the sixth digit of sin(double(pi)) is four then you have the correct value for sin(), but if it is zero then you have the incorrect fsin version.
Compile-time versus run-time sin
g++ tries to do as much math as possible at compile time, which further complicates this messy situation. If g++ detects that pi_d is constant then it will calculate sin(pi_d) at compile time, using MPFR. In the sample code above if pi_d is declared as ‘const’ then the results are quite different. This difference between compile-time and run-time sin() in g++ with glibc 2.15 can be seen with this code and its non-unity result:
const double pi_d = 3.14159265358979323846;
const int zero = argc / 99;
printf(“%f\n”, sin(pi_d + zero) / sin(pi_d));0.999967
Or, this equally awesome code that also prints 0.999967:
const double pi_d = 3.14159265358979323846;
double pi_d2 = pi_d;
printf(“%f\n”, sin(pi_d2) / sin(pi_d));
It’s almost a shame that these goofy results are going away in glibc 2.19.
Sine ~zero == ~zero
Some years ago I was optimizing all of the trigonometric functions for an embedded system. I was making them all run about five times faster and my goal was to get identical results. However I had to abandon that goal when I realized that many of the functions, including sin(), gave incorrect answers on denormal inputs. Knowing that the sine of a denormal is the denormal helped me realized that the original versions were wrong, and I changed my goal to be identical results except when the old results were wrong.
66 == 68
Intel describes their internal value for pi as having 66 bits, but it arguably has 68 bits because the next three bits are all zero, so their internal 66-bit value is a correctly rounded 68-bit approximation of pi. That’s why some of the results for fsin are slightly more accurate than you might initially expect.
Sin() is trivial (for almost half of input values)
For small enough doubles, the best answer for sin(x) is x. That is, for numbers smaller than about 1.49e-8, the closest double to the sine of x is actually x itself. I learned this from the glibc source code for sin(). Since half of all doubles have a magnitude below 1.0, and since doubles have enormous range, it turns out that those numbers with magnitudes below 1.49e-8 represent about 48.6% of all doubles. In the glibc sin() source code it tests for the top-half of the integer representation of abs(x) being less than 0x3e500000, roughly equivalent to <= 1.49e-8, and that represents 48.6% of the entire range for positive doubles (0x80000000). The ‘missing’ 1.4% is the numbers between 1.49e-8 and 1.
So, if asked to write a sin() function I will volunteer to do the easy (almost) half and leave the rest for somebody else.
References
Details of discrepancies in several of these instructions: http://notabs.org/fpuaccuracy/index.htm
The Inquirer mocking Intel: http://www.theinquirer.net/inquirer/news/1023715/pentium-10-years-old-real-soon-now
Intel acknowledging that using a software implementation of sin()/cos() might be wise: https://software.intel.com/en-us/forums/topic/289702
Linus Torvalds believing the documentation: http://gcc.gnu.org/ml/gcc/2001-08/msg00679.html
The Intel documentation has caused confusion seen in this pair of bugs: https://gcc.gnu.org/bugzilla/show_bug.cgi?id=43490 and https://sourceware.org/bugzilla/show_bug.cgi?id=11422.
100,000 digits of pi: http://www.geom.uiuc.edu/~huberty/math5337/groupe/digits.html
Range reduction done right: http://www.imada.sdu.dk/~kornerup/papers/RR2.pdf
gcc 4.3 improvements including using MPFR for transcendental functions: http://gcc.gnu.org/gcc-4.3/changes.html
Intel’s blog post discussing fixes to fsin documentation: https://software.intel.com/blogs/2014/10/09/fsin-documentation-improvements-in-the-intel-64-and-ia-32-architectures-software
Java bug report that covers this: http://bugs.java.com/view_bug.do?bug_id=4306749
Nice explanation of another extreme fsin error: http://www.reddit.com/r/programming/comments/2is4nj/intel_underestimates_error_bounds_by_13/cl54afb
Three reddit dicussions of this blog post: programming, math, and hardware
Hacker news discussion: https://news.ycombinator.com/item?id=8434128
Slashdot discussion: here
Calculating Pi using sin() in a Google search (seen on reddit)
Calculating 60+ digits of Pi using sin() in a Wolfram Alpha search
An analysis of precision across various math libraries, functions, and precisions, showing that sin can be almost correctly rounded by many math libraries.

In theory, would it work to work around this by reducing the value by hand to between -pi/2 and pi/2, then calling fsin? Slower than just calling fsin, but much faster than an open-coded sin.
Yes, that would work. However the sin() implementations I’ve looked at just do the whole thing in software.
this may be an ancient thread and i’m not sure if anyone will read it but won’t that approach possibly create problems when adding or substracting n*double(pi)? but then again i suppose that trying to compute the sine of something stupidly large like 20 000 000 is futile anyway since floats are very grainy at that point
Range reduction is tricky but it is also well studied, and I believe can be done well, if that is important.
In most cases sin(large) is just a bad idea, agreed. On the other hand, sin(double(x)) always does have an actual best answer, and philosophically at least I like to know that there are sin() implementations that can calculate it.
Put another way, with very large numbers two adjacent doubles may be many multiples of pi apart, which makes sensible trigonometry ‘tricky’ to say the least. And yet, those numbers still have a best value for sin(x).
It’s reasonable for fsin to handle those poorly, as long as that is documented as such.
Could be interesting compare the results of this with D langauge, using dmd and gdc (gcc backend), with double and real types. Real type on D language, try to use the longest float point on the system, ie x87 FPU on a PC, when the Double type is the the typical 64 bit float
There’s absolutely nothing whatsoever intersting about D language. It’s a dull and uninspired C++ clone with very little to offer.
So you perhaps never used it. If you know the power of the CTFE, mixins, static if …… But this place is not for begin a stupid language wars. Here we are talking about a old problem of the x87 FPU
As someone who used D, I agree. But the guy who handled the math library seemed to have some talent.
How did you go about contacting Intel about the fsin problem? In my experience it can be really tough to just get through to the right people.
I know people.
Here small code for better demonstration (gcc+glibc):
/* usage example: * a.out 1 2 3 4 5 * this will print results for 1*M_PI, 2*M_PI, 3*M_PI, 4*M_PI and 5*M_PI */ #include <math.h> #include <stdio.h> #include <stdlib.h> int main(int argc, char *argv[]) { for(--argc, ++argv; argc; argc--, argv++) { int m; double x; if(1 != sscanf(*argv, "%d", &m)) { fprintf(stderr, "Can't parse number from `%s'\n", *argv); exit(1); } x = M_PI * m; printf("sin(%lf) == %.33lf == %.33lf\n", x, sin(fmod(x, M_PI)), sin(x)); } return 0; }“But Intel doesn’t use a 128-bit approximation to pi. Their approximation has just 66 bits. Here it is, taken from their manuals:
C90FDAA2 2168C234 C”
But “C90FDAA2 2168C234 C” is 68 bits, not 66 bits.
They talk about in the manual. They say the extra two bits are just for padding. However it turns out that the next two bits are supposed to be zero, so they could legitimately describe it as a 68-bit constant. Why don’t they? Ask Intel.
I would like to examine this further on other hardware platforms (IBM mainframe plus PowerPC, SUN, & HP distributed processors, all non-Intel). Could you provide a single program that could be compiled and run elsewhere (attempted at least) across multiple platforms to see how those fare (produce printed output or binary files if necessary).
Your best bet is probably the windows utility referenced on Scott Duplichan’s page at http://notabs.org/fpuaccuracy/index.htm
Note that none of those CPUs you’ve mentioned has instructions for transcendentals (sin, cos, exp, etc). They all rely on software implementations.
Even on x86 CPUs, the trend is to use software implementations for those functions.
Well, not entirely true. The IBM PowerPC in the RISC/6000 has a “complex” instruction set (note the irony), with built-in hardware (microcode or firmware) for many of the instructions or functions being discussed here. But using software implementations does not necessarily mean they are doing it right. Testing will bear out how close to correct they are. Early Apple computers (Apple II, Macs) did not have hardware floating point, and made use of the SANE software package (IEEE based specifications). Yet, during my tenure using an Apple IIgs, one company came out with an FPU card that fit in a slot, which also was built to those IEEE specifications, including jumping from 64 bit floating point to 80 bit floating point). When installed, it replaced all the equivalent SANE functions, and we simply believed they were correct (with some justification, of course).
By the way, that FPU card cost more in the 90s than a whole computer does today.
Could you give an example of how this would affect the every day computer user?
This will affect programmers who then have to work around the issue so that every day computer users are not affected. The developer of VC++ and glibc had to write alternate versions, so that’s one thing. The inaccuracies could be enough to add up over repeated calls to sin and could lead to errors in flight control software, CAD software, games, various things. It’s hard to predict where the undocumented inaccuracy could cause problems.
It likely won’t now because most C runtimes don’t use fsin anymore and because the documentation will now be fixed.
Doesn’t this expose that your overall pi approximation method is really just a way of extracting the value of the pi constant used for argument reduction?
That’s a cool way of looking at it.
Pingback: Floating-Point Determinism | Random ASCII
Do you honestly expect people to to know that “quintillion” means 10^18?—Why not write it in a comprehensible manner?
One could just as well say “do you expect people to know that 10^18 means quintillion?” Large numbers are not familiar to most people in any notation. Note, also, that in C and C-like languages, used throughout this article, 10^18 is 24, so your suggestion depends on the reader knowing from context that just this time, ^ has a totally different meaning.
“Intel Underestimates Error Bounds by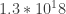 .” looks decidedly unequivocal to me.
.” looks decidedly unequivocal to me.
Haha, Muphry’s law in action?—the blogger would have finer control over the title though!
I don’t know if I can do superscripts in wordpress.com titles, and even if I can they would map poorly to a URL name. Quintillion has the advantage of being less ambiguous when googled, although to be really clear I should have said “1.3 exa ulps”.
I thought that the names of the large numbers in english are easy to remember if you know how numbers in latin are named. One just divides the tens power by three and subtracts one. For example 10^18 : 18/3-1=5 Latin “quinque” gives quintillion; 10^33 : 33/3-1=10 Latin “decem” gives decillion; 10^12 : 12/3-1=3 Latin “tria” gives trillion. There are only two exceptions in American English, 10^6 and 10^3.
Well, quintillion does mean 10E18 except when it means 10E30.
Yep, British naming for the large numbers is different, with billion/trillion/quadrillion/quintillion being one million raised to the 2nd, 3rd, 4th, and 5th powers respectively. I usually avoid saying ‘billion’ because of this ambiguity, although I think the (more consistent) British names are losing out.
On my Ubuntu 12.04 box it seems that sin() is fixed (i.e. 6th digit is 4 not 0), but not sincos()!
That’s fascinating that sin() and sincos() are behaving differently. I suspect compile-time versus run-time implementations. That is, I think your optimization level is affecting the results. Things to check:
glibc version: 2.15 has the bug, 2.19 does not
32-bit versus 64-bit: 32-bit has the bug, 64-bit does not
Generated code: calls to sin() have the bug, compile-time does not
So, the bad values from using fsin only show up if you are using glibc on 32-bit such that the compiler actually makes a call to sin(). The last one is tricky to verify.
Yes, it seems to be fixed on a later version (64-bit 14.04 running in a VM).
That is because sincos was implemented using the fsincos instruction. This was later fixed, some time in 2012 IIRC.
When needing a sin() and cos() function for rotation matrices, I was so frustrated with the lack of precision guarantees, that I decided to make my own implementation.
By using Mapping sin(a) with a > Pi/4 to cos(a – Pi/2) and sin(a) with a < -Pi/4 to -cos(a + Pi/2) I'm reducing the range to -Pi/4 to Pi/4. I've done so under the assumption that the Taylor Series works best around a = 0.
Did I overlook something? Is reduction to ±Pi sufficient?
I believe that reducing the the +-Pi range will work poorly, so you did right. Just make sure you do the reduction well in order to avoid this problem.
After I wrote that question I gave it a try. Instead of reducing the range to ±Pi/4 by referencing sin()→cos() and cos()→sin() I only reduced it to ±Pi/2 by self-referencing sin()→sin() and cos()→cos().
The result of my test run was bit-perfect the same output. So I conclude, as far as double precision math goes it doesn’t matter.
Kami – you have the right idea, but think in radians not fractions of Pi.
Consider the Taylor Maclaurin series for each:
sin(x) = x – x^3/3! + x^5/5! – x^7/7! + x^9/9! – x^11/11! + x^13/13! – x^15/15! + . . . and
cos(x) = 1 + x^2/2! – x^4/4! + x^6/6! – x^8/8! + x^10/10! – x^12/12! + x^14/14! – . . .
To achieve the greatest precision with the fewest terms, keep x < 1 (~ 57º). The key to speedy computations is
1) to table an array of the inverse factorials (constants). and
2) compute x^2. Each term in either equation is the previous term times x^ times InvF(i)
If you keep x<1, precision is automatic. If you need 10^-35 precision cos(), you'd need 16 terms (ends with + x^30/30!) and the precision is better than the 17th term -x^32/32! or 3.80039075e-36 (at worst). For sin(), you'd also need 16 terms (ends with – x^31/31!) and the precision is better than the 17th term -x^32/32! or 1.15163356e-37 (at worst).
Today, I generally use my own T/M Sin and T/M Cos routines because I only need about 1.0e-5 precision when drawing to my screen or 1.0e-6 going to the printer.
Even at double precision, my software was 2.4 to 3 times faster than the original Pentium chips. Not true today.
One other observation. If I needed this level of precision, I'd sell the wife and get a good XEON system. (only kidding – about selling the wife).
Please, I beg you, do not use the Taylor series. Find a Minimax approximation if you are going the polynomial route, although 33 entries in a table are enough for 1e-9 accuracy on single floats using range reduction and reconstruction. http://www.research.scea.com/gdc2003/fast-math-functions.html
Thanks for the pointer. I’ll definitely look into it when I find the time.
Right now the performance of sin()/cos() is completely negligible. You need them to create a rotation matrix which in turn is applied to thousands of coordinates. In my last profiling run
108111 calls of the cos() function for
46370280251 rays cast, which in turn led to
114611272720 calls to the Gaussian Elimination function.
Hi, I have combined the two given programs in one and here is what I get as a result. I haven’t change code just put them in one file. My CPU is AMD Athlon 64 x2 4200+ Brisbane compiler g++ 4.9.1 on Debian testing.
$ ./a.out 1 2 3 4 5
sin(3.141593) == 0.000000000000000000000000000000000 == 0.000000000000000122464679914735321
sin(6.283185) == 0.000000000000000000000000000000000 == -0.000000000000000244929359829470641
sin(9.424778) == 0.000000000000000000000000000000000 == 0.000000000000000367394039744205938
sin(12.566371) == 0.000000000000000000000000000000000 == -0.000000000000000489858719658941283
sin(15.707963) == 0.000000000000000000000000000000000 == 0.000000000000000612323399573676628
PiAddition
pi = 3.141592653589793115997963468544185
+ 0.000000000000000122464679914735321
= 3.141592653589793238462643383279506
Would it make sense to introduce another instruction (or pass a second argument to FSIN) to calculate sin(pi*x) instead of sin(x)? The argument reduction will be fast and error free. That way people caring about accuracy around integer multiples of pi can reformulate their calculations to take advantage of this.
If such a technique makes sense then it should be done in software, not in hardware. The whole concept of an fsin instruction is from another era. It is not something that hardware can do significantly better.
IEEE 754-2008 specifies sinPi(x) = sin(pi*x) and cosPi = cos(pi*x) functions to avoid this range reduction problem, but not tanPi (while tan has the same problem).
I am surprised that FSIN is indeed still used in some semi-recent variants of glibc (in 32 bit builds). I was of the impression that all those “special” math routines have been disused and replaced by software versions for at least 10 years, which are much faster in practice. (well, that seems to be the case for exp() at least).
Avoiding fsin was discussed about a decade about but (as shown in the link from “up-and-coming Linux kernel programmer”) Linux Torvalds believed Intel’s documentation and said that it wasn’t necessary. If the documentation had been accurate then sin() would probably have been updated then.
A semantics comment: “sin” is the symbol to represent the function known as “sine”. So I might write “sin(pi)=0” or, “the sine of pi is zero”.
Thanks for the semantics suggestion. I’ve changed a few instances of sin to sine. It’s subtle but could arguably make the rhetoric more clear and correct.
It looks like James Gosling (or rather Joe Darcy) was also aware of the issue with fsin argument reduction (https://blogs.oracle.com/jag/entry/transcendental_meditation), which explains the Java overhead and gnashing of teeth.
Way back around 1982, I was working as a research assistant for Cleve Moler, he of MATLAB fame. He has always been keenly interested in trig function algorithms and implementations. We tested the IBM 360 libraries and the then brand-new Intel 8087 to measure the error rates. We found the 360 trig functions displayed enormous errors around certain values, and so did the 8087, somewhat less severe. He tested simple algorithms that used a small table of values to adjust results as the calculation proceeded and provided less than 1 bit errors across the entire function. However, the idea of using up valuable RAM to hold a few dozen bytes of table data seemed outlandish, I don’t know if it ever went anywhere. I’m not surprised a hardware implementation of sine would have the kind of errors described here.
I’ve been trying to think of an example of when this error would be anything that would have any real effect; a picture would look wrong, a satellite would miss its orbit, a protein folding would be calculated incorrectly, a bank transfer would be incorrect. I’d love it if somebody would suggest a way this could have any kind of practical effect at all — I’m certain that there is, but I just can’t see it.
Perhaps some sort of simulation, or something where the internal inconsistencies cause issues. I’m not actually sure. It’s hard to say because issues caused by this would probably be found in test and the developers would then work around them, perhaps by not using fsin.
You should ask this guy:
http://hardware.slashdot.org/comments.pl?sid=5812911&cid=48115197
A general question here is how does the ‘accurate’ software version compare to the hardware FSIN/FCOS/FSINCOS implementations in terms of speed?
Now I know that “fast and inaccurate” is not often a good idea, but I can imagine a lot of cases where either the angles are small or only float accuracy is needed, and if the speed is different bu an order of magnitude then it might be worth considering.
It depends. The glibc math functions for 64-bit computations should be correctly rounded. This means that for y = sin(x) the value of y is the closest possible floating point number to the ‘true’ sin of x. The performance of correctly rounded math functions is highly variable (input dependent). Indeed, at least for the pow(…) function there are some degenerate cases that be 10,000 of times slower than ‘usual’.
Thankfully no one in the scientific community uses either the glibc math functions (except when the algorithms depend on the results being correctly rounded) or the x87 unit in general (SSE/SSE2/AVX has taken its place even for scalar computations). A decent vector math library should be ~10 or so times faster than the x87 transcendental functions (double precision) with errors on the order of ~1 to ~2 ulp.
It is worth pointing out that the x87 functions are not ‘in silicon’; they are almost all in microcode nowadays. Hence, Intel can probably fix the error if they wanted to with a microcode update. (They wont as the issue affects ~0 real world applications.) Indeed, the fact that these instructions are in microcode is one of the reasons why they are so slow. As a reference point on a Haswell CPU fsin can take between 47 and ~100 or so cycles. A Pentium IIII chip takes between 27 and ~100 or so cycles for the same operation. Or, in other words: no improvement beyond clock speed over 16 years.
Do you have any references for the correctly-rounded claim for glibc? I hadn’t heard that and, I wasn’t even sure if it was provably possible for double precision. I did a few quick searches and I just found references like these (https://gcc.gnu.org/ml/gcc/2012-02/msg00469.html and https://gcc.gnu.org/bugzilla/show_bug.cgi?id=52593) from 2012, both mentioning imperfect rounding.
I’m genuinely curious. Better rounding than fsin seems pretty easy, but correctly-rounded is a tougher challenge, and correctly rounded across a wide range presumably has limited benefits so it would be fascinating if they had decided to go that far.
BTW, the handy thing about software implementations is you can (if you have the source and the time) choose your own tradeoffs. This can include performance, precision, and supported range. Instructions for things like sine and cosine can’t offer that sort of flexibility.
Correct Rounding was a goal for IEEE754-2008 which was to have a section on accuracy for transcendental functions. They stumbled over this little thing of the “Table-Maker’s Dilemma” – how many digits must you generate before you can know which way to round the final digit? The worst cases along the FP number line are shockingly large, certain theoretical values are “Entscheidungsproblem” hard.
Click to access aoc2000-11.pdf
For sin in glibc see: https://sourceware.org/git/?p=glibc.git;a=blob;f=sysdeps/ieee754/dbl-64/s_sin.c;hb=HEAD#l281 Incidentally, this is why the glibc math functions have such a poor reputation in the scientific community — correct rounding is expensive and clearly not amenable to vectorization.
Provably correctly-rounded math functions were something of a novelty a decade ago. However, quite a bit of that changed when crlibm came onto the scene: http://lipforge.ens-lyon.fr/www/crlibm/
The trend nowadays is towards cheap hardware approximation functions. We already have them in SSE as RCP and RSQRT for getting a cheap approximation to 1/x and 1/sqrt(x) which the user can then polish with a Newton iteration or two. These will be extended further with AVX-512 (ERI). Similar instructions are already available on the Xeon Phi.
Indeed, now we have fused multiply add instructions available the days of hardware double precision div and sqrt are numbered. Expect the throughput to remain flat or even regress in the coming years. This already happened when AVX was introduced; we got 256-bit variants of sqrtpd and divpd but the latency is ~double that of the 128-bit variants. Incidentally, NVIDIA GPUs do not have double precision variants of either of these instructions — they use FMA operations to polish single precision approximations.
Cool. The sin in glibc source code that you link to (which, in hindsight, I realize I saw a few days ago) has this comment block:
/* An ultimate sin routine. Given an IEEE double machine number x */
/* it computes the correctly rounded (to nearest) value of sin(x) */
To clarify your comment, the reason the scientific community might not find this ideal is because this sin() function is accurate but not necessarily fast. Also note that the source code lists the cutoff point below which sin(x) == x — handy.
To those who aren’t familiar with the tradeoffs of implementing sin/division/etc. in hardware versus software, hardware has very few inherent advantages for this (the same operations must be done) and using software means that the ever improving out-of-order processing engine can improve performance. Plus software is more flexible.
Thanks for the detailed comment.
The inaccuracy of FSIN/FCOS and buggy documentation has been known for more than 10 years. I had found this web page at that time: http://web.archive.org/web/20040409144725/http://www.naturalbridge.com/floatingpoint/intelfp.html
Concerning the correct rounding of sin and cos in glibc, this is just a conjecture; but AFAIK, it computes up to 768 bits, which should be highly enough (there has also been a bug in the past, but now fixed). The hardest-to-round cases are not known for sin/cos/tan functions. For the best known algorithms to find them: http://hal.inria.fr/inria-00126474 (but this would still require many years of computations).
About sine accuracy with GCC + glibc, you can also see https://www.vinc17.net/research/slides/sieste2010.pdf slides 11 to 15.
Thanks for the references — the INRIA paper is pretty cool and does seem to support your belief. I’ll have to play around with that.
Well, Slashdot has picked up on this, including a reference to other Intel CPU errors with math…
Where Intel Processors Fail At Math (Again)
http://hardware.slashdot.org/story/14/10/10/193217/where-intel-processors-fail-at-math-again
Reblogged this on O(lol n) and commented:
Do checkout Pentium FDIV bug too
Remember that fsin is a x87 instruction, and that x87 has been deprecated for a decade.
Also, the documentation does clearly say that only 1 ulp is guaranteed for values that are in range.
Range reduction is extremely costly to do accurately, which is why they chose not to do it, especially since it is a 80-bit computation. Once truncated to 64-bit, the result is correct but except for very large values.
> x87 has been deprecated for a decade.
But x87 is part of the 32-bit ABI so that ‘deprecation’ is not very meaningful. x87 continues to be unavoidable, and x87 continues to be used.
> the documentation does clearly say that only 1 ulp is guaranteed
Yes, it does. Which is why the error of 1.3 quintillion ulps is notable. The documentation is wrong, as Intel has agreed.
> Once truncated to 64-bit, the result is correct but except for very large values.
No it isn’t. The 64-bit result from a (small) 64-bit input has only 13 bits correct — 40 bits of zeroes.
No one serious about floating-point uses 32-bit. It’s ancient, and the ABI precisely causes large problems because of its usage of x87. Move to amd64 like the rest of the world.
I see that your glibc results are also based on the 32-bit variants, something that anyone in its right mind shouldn’t be using at all.
I see you conveniently quoted only part of my sentence. 1 ulp is only guaranteed *when the input is in range*. This also appears in the original documentation.
There are many types of software (games, for instance, but also many others) where 32-bit support is still required. Unfortunately enough consumers still use 32-bit operating systems that dropping 32-bit support is not always practical.
The “in range” part of your statement doesn’t really change the meaning because the range is defined elsewhere in the documentation as being +/- 2^63. pi is well within that range.
Are you actually suggesting that the current documentation is correct? Because even Intel doesn’t believe that — see their blog post from Thursday that I link to.
There is no good reason for games to run on 32-bit, even if a lot still do so due to special legacy issues that only people in the field would know. All hardware that has been released for ten years is 64-bit compatible, and games require relatively recent hardware.
I think most or all PC game developers would *love* to release their games as 64-bit only. And yet, so far most of them have not. That is because a non-trivial number of customers still run 32-bit operating systems — sometimes on quite new hardware. Yes, this is annoying. But it is reality, especially for games that have are targeting a Chinese market where 32-bit Windows XP is quite common.
I’m curious; does anyone have a non-contrived, real world example where this apparent deficiency in the documentation for the FPU has a genuine practical significance?
In most real world applications, the argument for the sin() function will be arrived at through computation. The argument will therefore be subject to the normal errors which arise in such FPU computations, meaning that in general there will be an error in the argument of the order of a ulp or more. The extra error of a fraction of a ulp due to the FPU approximation of pi will therefore by minor in almost all cases.
Some years ago, I had a brief look at the issue of the accuracy of the FPU approximation of pi and put a few notes in a README which can (or could) be found in the Linux kernel sources, or in places such as:
https://www.kernel.org/doc/readme/arch-x86-math-emu-README
This gives the example of the integer 8227740058411162616 which is close to an integer multiple of pi and would require an approximation for pi with around 150 bits of precision in order to reduce the argument to a 64 bit precision number in the range +/- pi/2.
There’s a maths graduate on Slashdot who says that hardware instructions or anything less than “Maple, Matlab, Mathematica and similar” is insufficient. He certainly claims to know when this extra accuracy is necessary, but I’m not sure if he’ll explain.
http://hardware.slashdot.org/comments.pl?sid=5812911&cid=48115197
Are you implying that being a math graduate makes someone an expert on numerical computing and floating-point arithmetic?
That’s not quite the case. Even among professors and researchers specialized in these field, there are relatively few experts.
I am thoroughly unconvinced by his/her claims. Firstly, s/he claims:
“I’ll tell you now that I wouldn’t rely on a FPU instruction to be anywhere near accurate. If I was doing anything serious, I’d be plugging into Maple, Matlab, Mathematica and similar who DO NOT rely on hardware instructions.”
Grouping Matlab in with Maple and Mathematica — both of which have arbitrary precision arithmetic capabilities is an immediate red flag. Matlab uses the floating point capabilities of the underlying hardware (single or double precision) and not arbitrary precision.
“Nobody serious would do this. Any serious calculation requires an error calculation to go with it. There’s a reason that there are entire software suites and library for arbitrary precision arithmetic.”
In the majority of physics and engineering applications the error from either the model or in the uncertainty of the initial conditions dominates. It is unusual for issues to come about due to accumulation of round-off errors. This is especially true when working at double precision. (One would be surprised just how many engineering packages — both open source and commercial — run in single precision without issue.)
As an example if I want to work out the circumference of a circle with a radius of 1m and use a value of pi good to 10 decimal places then the resulting error will be measured in the vicinity of 1e-10; or similar to the radius of an atom. Irrelevant.
“And just because two numbers “add up” on the computer, that’s FAR from a formal proof or even a value you could pass to an engineer.”
The addition of two floating point numbers (single or double precision) is specified to the exact with respect to the currently-employed rounding mode on all major hardware platforms. If this is round to nearest then c = a + b yield the closet floating point value to the ‘true’ value of a + b. While it is uncommon for manufacturers to provide formal proofs for their FPUs (AMD did many years ago, through), they are expected for the elementary operations to be compliant. Expect for the Pentium FDIV bug I am not aware of any evidence to the contrary.
Thanks for the detailed information. I was not aware of the distinction between MatLab and the others, and that is clearly important.
Regarding error accumulation, it certainly is possible to have errors accumulate if you use a poorly conditioned algorithm. However the fix is not to give up on hardware floating point, but to use a well conditioned algorithm or, in some cases, use double instead of float. I may have made both of these fixes in software I have worked on and the fixes have worked very nicely. Throwing arbitrary precision arithmetic at a problem when the algorithm is poorly conditioned is like using a sledge hammer on a thumb tack.
That is almost the definition of numerical analysis: doing maths by means of algorithms that deal with the limited precision and execution speed of real-world computers!
As has been mentioned already, the issues with large arguments to trigonometric functions are well known and the relationship of accuracy to the approximation for pi that is used in argument reduction. The 66bit approximation of pi used in Intel X87 hardware implementations certainly will afford large errors for large arguments, which Intel developers certainly knew and documented.
The trigonometric functions implemented in Sun/Oracle libm/libsunmath/libmopt have for a long time used a so-called “infinite” precision approximation of pi, i.e. enough bits to guarantee a sufficiently accurate argument reduction to afford less than 1 ulp error even for large arguments to trig functions.
For a few years Sun/Oracle also made available the source code for libmcr, a library of common transcendental functions, including the trig functions, that produced correctly rounded results (i.e. the algorithm used was proved to compute correctly rounded results subject to the correctness of the implementation). What was not determined, though, was the upper bound of computation time due to the aforementioned problem of not knowing the maximum number of bits necessary for “hard” cases.
I don’t think that the issues with large arguments to trigonometric functions were “well known” except in a very narrow community — I know more than most about Intel floating point and I had no idea.
And, while I agree that the Intel developers new about the argument reduction issues they were *not* documented. If they were always documented then Intel wouldn’t have done a blog post on Thursday (linked from the fourth paragraph) detailing the doc fixes they will make. That is, the 66-bit approximation of pi was documented, but its implications were not documented — the documentation actually denied them.
I have a genuine question about this – just how important is “correct rounding” to 1 bit?
Given you already have finite precision, would having, say, 3 bits maximum precision extension so you have a 87% probability of 1 LSB correctness and 13% chance of it extending to 2 LSB error, be good enough to deal with the “table maker’s dilemma” and a provable limit on computation time?
For the basic operations, absolutely critical, since otherwise error analysis is impossible. And, there are times with sin/cos, I am sure, where perfect rounding is critical, although I am sure they are less common.
Getting to within 1 ULP of the correct answer is not, I believe, too hard. Getting the rounding perfect can be much trickier.
One significant advantage to perfect rounding is that makes for consistency. Right now every sin() function is different, so code can break in subtle ways during compiler upgrades or when moving to a different machine. If perfect rounding is available everywhere then perfect consistency is available everywhere, and *that* is hugely valuable.
Am I right then in thinking that “perfect rounding” is 0.5 ULP, and if you don’t quite get that then you could be 0.50000…1 ULP away due to the “Table maker’s dilemma”?
I am not an expert in numerical analysis but I have written a lot of number crunching software, and I never expect to have perfect consistency from one compiler to another, nor from one optimisation level to another!
This is due to things like how the code is optimised (i.e. order of operations), and if the FPU uses higher internal precision along with temporary variables in the FPU registers (typical of the x87 family), rather than writing it out at float/double/etc. So while I can appreciate that NA folk would like to have such a degree of consistency for error analysis, my usual feeling is if it going to be a problem then you have an unstable algorithm in the first place, and you really need to address that first long before you worry about 1 or 2 ULP.
A few quintillion ULP is, of course, a rather different matter!
Perfect rounding is defined as being equivalent to taking the infinitely precise result and rounding it according to the current rounding mode, which defaults to round-to-nearest even (ties go to even answers). In this default mode the maximum error is 0.5 ULP. This is easy to implement for add/subtract/multiply/divide/square-root, and tough for sin/cos.
You are correct that order of operations and other factors can make getting identical results extremely difficult (see https://randomascii.wordpress.com/2013/07/16/floating-point-determinism/ for a discussion of many such factors). Given how hard determinism is, any time that one of the problems can be removed it is very helpful for those who need determinism.
As floating-point moves away from x87, and as the rules are strengthened, determinism is becoming far more practical. Because of that, and because tight error bounds are better than sloppy/uncertain error bounds, I think that provably correct transcendental functions are a nice step forwards, even if they will not affect most developers.
If you want to see how much math functions are different: https://www.vinc17.net/research/testlibm/ (this is rather old, though). And FYI, an article about the possible importance of reproducibility in games: http://www.gamasutra.com/view/feature/131466/ (page 3 mentions floating point). IMHO, languages and implementations should provide features to let the developer control the accuracy, the reproducibility, and so on, depending on his application. In C, you have some pragmas, such as STDC FP_CONTRACT, which is a first step; unfortunately broken in GCC: https://gcc.gnu.org/bugzilla/show_bug.cgi?id=37845
I posted a link to this on my CPU Museums blog, comparing it to the Pentium FDIV bug of 1993-4. Interesting both are/were the result of hard coded values.
http://www.cpushack.com/2014/10/15/has-the-fdiv-bug-met-its-match-enter-the-intel-fsin-bug/
An interesting comparison, but I think that the fdiv bug was *far* more serious. It was impractical to work around and it could hit almost any software, because division is one of the core operations used to implement higher-level math operations, such as a software implementation of sin(). A bad fdiv can make implementing sin() difficult, but not vice-versa.
Certainly would agree with that, possible to work around, but certainly not easy, and at a time when Intel really didn’t need the bad PR, they had a lot more competition then.
I enjoyed your floating point articles that I decided to look at how msvcr100.dll implements sin(). sin(double(pi)) is correct, and when x is restricted to some range (around [-28000pi, 28000pi]), around 15/10000 values of sin(x) are 1 ULP off, the rest are correct.
msvcr100 uses a 122 bit value of pi, Cody and Waite’s method is used for range reduction. The interval [0, 2pi] is divided into 64 equal regions, then sin(x) is computed using a 9th order Taylor series approximation around the center of the region containing x. Kahan summation and some other techniques are used improve accuracy. I’ll probably write a complete analysis some time.
Very cool. How did you find this out? IIRC VC++ doesn’t publish source code for the math functions — did you derive this from the assembly code? It would be interesting to look at the Dev 14 CRT (VMs in Azure available) to see if they’ve changed it at all.
From the disassembly of the DLL. The algorithm is the same from msvcr80 to msvcr120, SSE2 is used for arithmetic. The older ones use FSIN. I haven’t looked at appcrt140, I’m still looking for a copy of the DLL without downloading VS14.
appcrt140.dll uses the same algorithm
Here is a C reconstruction with a bit of explanation: http://pastebin.com/ruit6s2A
Nice C reconstruction. I opened a bug requesting that VC++ implemented correctly rounded versions. If you could annotate it with some examples where the result is incorrect that would be great.
https://connect.microsoft.com/VisualStudio/feedback/details/1004830
How do you report documentation bugs anyway? I spotted a small mistake in Vol2A and I was wondering how I can get it fixed.
Sometimes it seems like tweeting is the only way to get documentation bugs fixed, and that’s a pretty poor method. It is annoying when software projects or documentation websites don’t have a way of submitting feedback or bugs. The lack of formal ways to report Windows Performance Toolkit bugs is particularly frustrating to me.
Good luck.
Wait, “13 bits of precision” as in… 1 in 8192? Less than 5 decimal digits? So less accurate than “3.1416”? Capable of producing a hand-measurable error in a circle about 100ft across?
How did they miss that, then?
Mark, this is essentially a documentation bug. These operations implemented in hardware are intended to be fast. The loss of accuracy is here related to the range reduction, which can take time. There exist fast range reduction algorithms, but Intel hasn’t implemented one. The reason may be that they want to remain “compatible” with past processors. On this subject, at some time, AMD x86 processors were more accurate than Intel’s, and AMD users complained and reported bugs! Also note that in practice, even if fsin were correctly rounded, you would probably get the same loss of accuracy in your program, because the inputs would have to be represented with much more precision than the one supported by fsin (except in the very rare cases of exact inputs for fsin); see: https://en.wikipedia.org/wiki/Condition_number
Vincent has answered this quite nicely. I’ll just add that the expectation (poorly documented) is that users will do their own range reduction and therefore avoid these inaccuracies. Most sin() implementations have gone farther than that and just skip the fsin instruction entirely, in the case of glibc giving perfectly rounded results.
After some search on Google… What was done in the AMD K5 processor and reverted later is an accurate range reduction, i.e. fixing the issue discussed here. On https://blogs.oracle.com/jag/entry/transcendental_meditation (posted in 2005), it is said: “This error has tragically become un-fixable because of the compatibility requirements from one generation to the next. The fix for this problem was figured out quite a long time ago. In the excellent paper /The K5 transcendental functions/ by T. Lynch, A. Ahmed, M. Schulte, T. Callaway, and R. Tisdale a technique is described for doing argument reduction as if you had an infinitely precise value for pi. As far as I know, the K5 is the only x86 family CPU that did sin/cos accurately. AMD went back to being bit-for-bit compatibility with the old x87 behavior, assumably because too many applications broke. Oddly enough, this is fixed in Itanium.”
Interesting problem! Our recent research paper (OOPSLA 2015, to appear) has attempted to understand this issue (Section 2, Example 2, in http://zhoulaifu.com/wp-content/papercite-data/pdf/fu15a.pdf).
It is possible that the issue raised in this post is due to bad conditioning (See N. J. Higham’s “accuracy and stability of numerical algorithms” about “conditionining”).
The problem here is just bad range reduction. The range reduction for numbers near Pi is done by subtracting a hard-coded Pi constant, and that constant has only a bit more precision than a double. In fact, hand adding of double(pi) + fsin(double(pi)) produces the exact constant that Intel uses, since the result of fsin(double(pi)) is just their reduction constant minus double(pi).
I see your point.
But, to blame your reported inaccuracy on the “range reduction” just does not help people to realize the deeper reason about this matter — the bad conditioning of your proposed procedure.
Here, it is useful that we realize that to calculate fsin(pi) correctly is highly difficult by nature, because of its high conditioning. In numerical analysis, your forward error (which is the kind of error we are talking about) is controlled by your backward error and conditioning number, where the condition number is known to be problem-dependent, but implementation-independent (see Higham’s book referenced above) — meaning that if your proposed procedure is badly conditioned, you will probably experience hard time to make your numerical computation accurate.
There have been many algorithms to estimate pi. IMHO, you proposed algorithm, namely, to calculate pi via sin(pi2) + pi2 (where pi2 denotes an estimated, inaccurate pi), looks appealing but turns out unacceptable, numerically.
Voila. I may be totally wrong or biased.
I get your point (more or less), but I think my method is still valid. It’s a stress test for sin implementations for sure – a stress test that VC++ handles well, and modern glibc implementations handle *perfectly*. At this point it is only Intel’s implementation (decades old and not changeable) that can’t handle my calculation.
Well conditioned algorithms are important to be sure. I fixed a function at my last job that had catastrophic cancellation that left close to zero digits of precision. The (trivial) fix caused it to give perfect (no rounding error) results. A clear win for better conditioning.
In this case, even though the range reduction is arguably a case of catastrophic cancellation, it is a situation that sin should handle. That’s its job.
Thanks for your feedback. But no, your method is highly sensitive to input errors, and therefore, *invalid* numerically. This sensibility is quantified by, as mentioned earlier, the condition number that is *born with* your proposed procedure.
Of course, when your procedure is too sensitive to input errors, you can always use the more precise glibc to compensate it. But this does not contradict with the fact that your proposed procedure behave badly from a numerical perspective.
To sum up, in your case, IMHO, do not blame Intel, but blame the way you estimate pi. Disclaimer: I am not affiliated with Intel.
To be clear, what I blamed Intel for was their inaccurate documentation, which was inaccurate. I believe it is fixed now.
I don’t think a method can be tagged as *invalid* numerically for being sensitive to input errors. There are some risks, certainly, which must be understood.
Anyway, the real problem was that Intel’s documentation was misleading. I certainly don’t expect them to change their implementation – but nobody uses it anymore so it doesn’t matter.
Thank you for your feedback. I have learned a lot through your blog. By the way, I guess people still use Intel’s FSIN today, for it should be much faster than the glibc’s. Not sure though.
The right approach would be to standardize a set of trig functions that scale their argument by 2pi or some other similar number. Most applications use angles that, if represented accurately, would be rational multiples of a circle. Outside of trying to read out the modulus used for range reduction, can you think of any non-contrived situations where an implementation which computed the double nearest the the sine of exactly x would be more useful than one which computed the double nearest the sine of some angle within 1/4ulp of x, or the x scaled by the ratio of “real” 2pi to the value closest to 2pi? Even computation of the behavior of a harmonic oscillator whose natural period would be 2pi seconds will only benefit if the step size is a power-of-two fraction of a second. If it isn’t (e.g. if there are 1,000,000 steps/second) optimal accuracy will require that range reduction be performed with a modulus of 2,000,000pi so as to get the value into the range +/-500,000pi before values are scaled by 1,000,000, so attempts to improve accuracy outside the +/-pi/2 range will be irrelevant.
Some games use integers to represent angles such that, for example, 4096 represents a full rotation. This allows for table lookup and allows sin(pi) (actually sin(2048)) to return exactly zero.
But to call this “the right approach” in general is to focus too much on this one tiny problem. Radians are the correct units for angles because they make the math for calculating sin/cos etc., whether with Taylor series, trig identities, or otherwise work out well. Coming up with yet another unit for measuring angles (we already have degrees, radians, and gradians) creates a large new problem while solving a small existing problem.
Besides, my bar trick of pi = rounded(pi) + sin(rounded(pi)) requires the use of radians.
TL;DR Radians are mathematically the right choice for angles.
I am well aware of why radians make sense in mathematics. What I have not seen are any non-contrived circumstances in which code which is interested in precision would want to compute trig functions on angles outside the range 0 to pi/2. Unless one has an unusual problem domain in which the only angles one is interested in are precisely equal to “double” values and never fall between them, getting optimal precision will require that range reduction be performed before computing trig functions’ arguments. I do not think it would be unreasonable to assume that any code which passes a value beyond pi/2 to a trig function isn’t really interested in precision.
I also know of no efficient algorithms for computing sines and cosines of radian-based angles which would not be more efficient with angles specified as power-of-two fractions of a circle. Having functions which operate on power-of-two fractions, along with some functions to convert radians to quadrants and vice versa would increase both speed and precision in cases where angles could be precisely expressed in units other than radians, and would have minimal effect in cases where angles would naturally be expressed as radians (a range-reducing radians-to-quadrants function which was designed for use with sin(x) would map values near pi/2 to values near zero, so “sin2pi(radToQuadForSin(x))” would be within one ulp of a perfectly-computed radian-based sin(x).
My understanding is that *all* of the efficient algorithms for computing sines and cosines use radians – you’d have to invent new algorithms or adjust the existing ones, probably with precision loss. Every time you converted from base-2-multiple-of-pi to radians you would lose precision, and the only time you would gain precision would be at exact fractions of pi.
Anyway, I don’t think that a new angle format is a good idea, and it will never happen anyway so it’s all theoretical.
The functions sinPi(x) = sin(pi x) and cosPi(x) = cos(pi x) are standardized by IEEE 754-2008 (my suggestion was to use the factor 2pi instead of pi, but it hasn’t been followed). I think that indeed sinPi may be faster than sin for small arguments; but this depends on the kind of algorithms: if polynomial approximations are used with coefficients obtained from a table look-up, then sinPi may be as fast as sin. But for large arguments, an accurate sin needs a complex range reduction, which may take time, while the range reduction for sinPi is really trivial; so, sinPi should be faster than sin in such cases.
Oops, I wanted to say the opposite for small arguments: sin should be faster than sinPi (assuming that the algorithms use the mathematical properties of sin, not raw table look-ups).
That makes more sense 🙂 . And indeed glibc’s sin function does a range check and for sufficiently small values of theta just returns theta.
I was curious about the 48% of doubles where x is near sin(x). It makes for a nice exploration of sin implementation and precision. The threshold is around 2.149e-8 on wolfram alpha.
http://www.wolframalpha.com/input/?i=plot+y+%3D+x-sin(x)+from+x+%3D+2.14911931e-8+to+2.14911935e-8
Curious. I wonder what precision wolfram alpha is using? I guess I could reverse engineer it if I really wanted to.
For double precision round to nearest even, the largest x where sin(x) = x is 2.1491193328908210e-8. It is a property of sin(), the precision, and the rounding mode.
In actual implementations of sin() the threshold for the “return x” case is usually lower. For example, the VS 2015 64-bit runtime (ucrtbase) uses 2^-27. For 2^27 < |x| < 2.149e-8, it will do some computations but the result should be equal to x.
I wonder whether there is a reason to use a lower threshold. The glibc dbl-64 generic case uses 2^(-26) by comparing the encoding with 0x3e500000: https://sourceware.org/git/?p=glibc.git;a=blob;f=sysdeps/ieee754/dbl-64/s_sin.c;hb=HEAD
Perhaps because the constant for the comparison is simpler thus faster to load? On the ARM, this would be the case for 0x3e400000 (2^(-27)), which fits on 8 bits with an even rotate, but not for 0x3e500000. If the VS 2015 source code is the same for the ARM, this could explain the reason.
Both the x64 library (FMA code path) and the ARM library does something like this:
if |x| < 2^-27:
return x
else if |x| < 2^-13:
return x – x^3/6
else: …
x64 compares the whole 64-bit value so the constants have to be loaded from memory. ARM (Thumb-2) compares the top 32-bit half. 2^-27 is an immediate but 2^-13 has to be loaded from memory. I don't know how much code is shared between the x64 and ARM libraries but here are my observations:
– They all use the same 13th degree polynomial approximation
– x64 (FMA) and ARM have the x – x^3/6 part while x64 (SSE2) does not
– Range reduction is different on all three
This has been interesting so far, maybe I will study the range reduction next.
It looks like Microsoft licensed the libm source from AMD. The early x64 CRT (msvcr80/90) and the ARM/ARM64 static library in the Windows 10 SDK seem to use this:
https://github.com/somian/Path64/blob/master/pathscale/libmpath/amd/w_sincos.c
x64 msvcr100/110 uses this:
https://github.com/simonbyrne/libacml_mv/blob/master/src/gas/sin.S
The newer x64 CRTs would get updates, like the FMA path in msvcr120.
Hi Bruce,
somebody mentioned your article on KvR, so I posted a reply
http://www.kvraudio.com/forum/viewtopic.php?p=6803619#p6803619
Digital Equipment Corporation VAX math library functions, circa 1978 and later did argument reduction for trigonometric functions by doing a 30000+ bit fixed point exact divide of the floating point
argument, including the exact 30000+ bit value of pi.
However, since the arguments were typically the results of floating
point operations and not exact values, the correct action would
have been to raise a loss of precision error.
For example arctan(X), were X is the result of a computation that
is stored as a quad rescission floating point number
actually has no value since the uncertainty in a result
that happened to be stored as 1Q50 is more than 2*pi.
So the arctan function should have raised a loss of precision error.
Then, if the programmer knew that X was actually an exact value
he could have let the result stand rather than setting the result to
NaN.
Q= real 16= total length 128 bits.
I worked at Digital at the time and reported the problem to the
developers they didn’t understand the loss of precision problem
and kept the accurate argument reduction of an inaccurate argument
stand with no error condition being raised.
> Since half of all doubles are numbers below 1.0
Isn’t that half of all positive doubles are numbers below 1.0? Or half of all doubles have a magnitude below 1.0?
Yep, good catch. Fixed.
Well. if you ignore the denormalized numbers, half of all doubles have a magnitude below 2.0
#include
#include
#include
void main() {
double a = DBL_MIN, b = DBL_MAX;
uint64_t c = (*(uint64_t*) &a + *(uint64_t*) &b)>>1;
printf(“%e\n”, *(double*) &c);
}
August 2018 hacker news discussion is at https://news.ycombinator.com/item?id=17736357
You are clearly not a hardware designer. Don’t make glib uninformed assertions about the discipline. Implementing trancendentals in micro code is also software and is not backward or obsolete. Doing so avoids clogging the cache with pervasive useful instruction sequences, and is intrinsically faster than software that needs to to be loaded from slow memory. Ideally, there would be a set of reserved opcodes, assigned to some default trancendental implementation, but whose micro code could be replaced by the user, either with improved algorithms, or with other specialized computations. The MMX architecture is a shadow of that idea – an alternate collection of micro code that uses the same x87 register set and combinatorial logic – it just does not permit user customization. It is the SSEx and AVX architectures that are broken, effectively pushing micro coding responsibility to the user in all cases.
It is true that I am not a hardware designer. However I have worked with many hardware designers and I’ve worked on software transcendental functions. And I am unconvinced by this claim:
“Implementing trancendentals in micro code…is intrinsically faster than software that needs to to be loaded from slow memory”
There are some things that hardware can do intrinsically faster, but it is not clear that micro code for transcendentals is one of those. The micro code interpreter and ROM take up valuable space that could be used more generically (for cache?), and for compatibility reasons they can’t be improved in subsequent generations.
If transcendentals in micro code was “not backward or obsolete” then I would be interested to know what CPU architectures in use today (other than x87) use this technique. Can you let me know what CPUs do? Because I’ve worked on ARM, Power PC, RISC, and Alpha CPUs and I don’t think any of them have transcendentals implemented in hardware. It seems odd that all hardware designers have abandoned this intrinsically better idea.
I’ve always liked this article that talks about costs and prices and why “just put it in hardware” doesn’t always work:
http://yosefk.com/blog/its-done-in-hardware-so-its-cheap.html
The link to http://www.imada.sdu.dk/~kornerup/papers/RR2.pdf is dead. Archived versions can be found on the Wayback Machine, e.g., https://web.archive.org/web/20030629012553/https://imada.sdu.dk/~kornerup/papers/RR2.pdf
Also, it seems there’s a revised version available here: https://perso.ens-lyon.fr/jean-michel.muller/RangeReductionIEEETC0305.pdf
There also appears to be a version on ResearchGate. I haven’t compared the versions yet, so I don’t know what the differences are between them. I suppose you can decide which version you want to link.
(And just for the sake of redundancy, DOI: 10.1109/ACSSC.2001.987766)
For a permanent location concerning articles by French researchers, you should use HAL. For the mentioned article: https://hal.inria.fr/ensl-00086904
I’d better start by saying that I understand that Intel made a specific technical claim that was incorrect. I also understand the IEEE definition of “correctly rounded”, etc.
That said… the digits in which FSIN differs from the “corrected” sine are noise. They only come into play when there is catastrophic cancellation during argument reduction, and in that situation, you just don’t know what those digits should be. They were lost earlier in the computation, before the sine function ever got the value. There is absolutely nothing that the sine function, no matter how “correct”, can do to fix this problem.
Kahan used to rant (and probably still does) about people saying that precision loss is caused by subtraction of nearby values. The point is that if catastropic cancellation occurs in a subtraction, then the important bits were already gone before the subtraction. The same thing is true here.
If a program calculates the sine of a number near a multiple of π, and it’s sensitive to many digits of the output, then it is doomed. It can only be fixed by subtracting the appropriate multiple of (exact) π from the argument before calling sin(), AND BACK-PROPAGATING THAT SUBSTITUTION THROUGH THE REST OF THE CALCULATION to the point where the relevant bits were shifted out of the register. When Intel says in its revised documentation “for accurate results it is safe to apply FSIN only to arguments reduced accurately in software”, they don’t mean (at least I hope they don’t mean) that you should write a wrapper around FSIN that subtracts a multiple of π to 128 places, because that WILL NOT WORK. It’s the same as the old sig-fig joke about the museum guide who says the dinosaurs went extinct 65,000,005 years ago because five years ago when they started working there it was 65 million years. You can’t add 128 digits of pi to a number that was previously rounded to 64 digits and expect the result to be accurate to 128 digits. That’s not how it works.
You link examples of people like Linus Torvalds being fooled by Intel’s old documentation. But you’re spreading a new and dangerous misconception: that now that the sine function has been “fixed”, it’s safe to pass values near multiples of π to it and trust that the output will be accurate to many places. That’s false, not in a trivial way but in a deep way that anyone who cares about numerical computation should understand. Although you say you understand floating point, I really get the impression that you don’t understand yourself that it’s false.
The original 8087 actually had a sensible way of dealing with this. It didn’t shift in made-up bits. Instead it produced “unnormals”, which are like denormals except that the exponent is not necessarily the minimum value. 1ulp is therefore not a roughly constant fraction of the value, as for normals, but is larger, effectively tracking sig figs. This feature was removed in the 80387.
I don’t have an 8087 or 80287 to test with, but I suspect that Intel’s documentation of the accuracy of FSIN and friends was correct when it was written, and they simply failed to update it when they dropped unnormal support in the 387. The accuracy of FSIN hasn’t changed. What has changed is the ulp. The output is now off by “1.3 quintillion ulps” because the ulp is now absurdly tiny, far smaller than could ever reasonably be justified for the given input.
I find the history of floating point computation really depressing, like the history of programming languages. The 8087 was “a great improvement on its successors”, to borrow a phrase that has also been applied to Algol 60.
The inputs are regarded as exact. This is important in order to ensure consistency when they are reused. For instance, one may want sin(x)*sin(x)+cos(x)*cos(x) to be close to 1, even when x is very large. Some algorithms require such properties.
Then, with a fixed exponent range and precision (like for single and double precision), it is possible to implement an accurate range reduction (still regarding the input as exact) quite cheaply by precomputing powers of 2 mod 2π (thus one avoids multiple precision).
I think I see your confusion. You are assuming that the 64-bit double approximation of PI which I was passing to fsin was the result of some prior calculation. In fact those bits were artisanally hand-crafted using the finest ones-and-zeroes which I hand picked in my roof-top garden. That value must be considered to be exact. To do otherwise would insult not only my own digit-picking skills but also those of my ancestors. It would be rude for my Intel math coprocessor to make assumptions about my bits also – it should really assume that its human master knows best.
I am very curious about your claim of unnormals in the original 8087. Citation needed, as they say. The float and double-precision formats don’t have such a concept and I’m not sure how that would work with the 80-bit format.
I think Kahan would agree that a sin function that calculates the sin of whatever it is given is in fact a useful thing. The fsin function cannot know and should not assume anything about the precision of its input. And, as I mention in this blog post, x+sin(x) is (for values of x at all close to pi) a rather nice way to get a more accurate value of pi. Catastrophic cancellation is something that developers must watch for. Having CPUs prematurely take liberties with it just makes things worse.
The glibc authors also seem to agree that a sin function that does what it is told, to full precision, is both worthwhile and possible.
Finally, while the x87 had some theoretical advantages it also has caused significant confusion for generations of developers. It is quite common for a developer to calculate the same thing twice and subtract it from itself (for legitimate reasons) and expect to get zero only to get something wildly different because the x87 can only round to float precision when storing to memory. Uggh. If you haven’t experienced the horrific unpredictability that this causes then you are very lucky. I for one am glad to be finished with it.
Concerning what Ben R said about unnormals, I suppose that he meant extended precision, for which the implicit-bit rule is not used. Indeed, according to https://en.wikipedia.org/wiki/Extended_precision, the 8087 and 80287 could generate unnormal results. But I do not think that this was intended (and that unnormal numbers were seen as numbers with a lower precision), and everything improved with the 80387. Similarly, https://en.wikipedia.org/wiki/Intel_8087#IEEE_floating-point_standard says “An important aspect of the 8087 from a historical perspective was that it became the basis for the IEEE 754 floating-point standard. The 8087 did not implement the eventual IEEE 754 standard in all its details, as the standard was not finished until 1985, but the 80387 did.”
Note also that IEEE 754 decimal floating-point formats have unnormalized values, but such values are still regarded as being exact, producing results in the full target precision, like in binary. The unnormal status is only used to convey additional information when all operations are exact (thus this is safe, but IMHO not much useful).